Stock Return Direction Prediction

Visit here to find my program written in Python.
My goal is to make daily predictions of the stock return direction for a specific US stock which leads to a profitable trading strategy. This problem is especially difficult because if we assume the efficient market hypothesis, then no strategy would ever truly work. In addition, individual stocks are more susceptible to noise than indices.
This article caught my eye immediately. L. Nevasalmi applied 5 different machine learning methods to make daily predictions of stock return volatility. The methods used appeared to have excellent long term predictability, as the test set contained data up to 11 years more recent than the training set. I transferred the features and methods used in their paper to my own binary classification problem for stock return direction, where random forest scored the most consistently.
I used data from the most recent 10 years because many current US stocks weren’t listed before that. Furthermore, with Yahoo Finance providing almost real time information, it would be easy to convert this pipeline for real world applications.
L. Nevasalmi considered all predictors from the past 10 trading days. I doubted that I would need that many days of input, since many papers related to daily stock return direction classification utilized predictors from only the past day. I constructed a test to provide evidence for this:
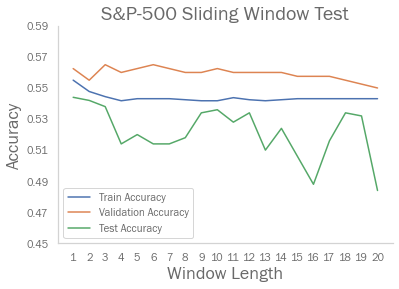
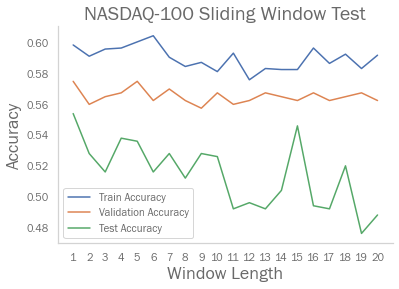
The NASDAQ-100 and S&P-500 indices have -0.67276502 and -0.47169106 correlation coefficient between test accuracy and window length respectively, suggesting that a window length of 1 is better for this situation. This article further supports my speculation, in which they concluded “the highest prediction performance is achieved when the input window length is approximately equal to the horizon which the predictive system is designed to forecast”.
To address the class imbalance problem, I tried oversampling and SMOTE. Sampling techniques presented some success but often decreased accuracy. Instead, I used validation data to adjust the threshold line for classification, resulting in the increase of accuracy among other metrics.
This paper analyzed the usage of technical analysis on prediction of stock price direction. They compiled a list of TA features that was used in recent financial prediction papers, and another list for predictors used in market. I took 34 of the features from the literature list and added it to my previous inputs.
At this point there may be too many features which contribute too little to be useful, because they give the predictor opportunities to overfit. I used recursive feature elimination to reduce low importance features.
In order to test the current method’s capabilities in relation to my goal, every single component stock of S&P 500 is trained and tested on it. S&P 500 is a fair representation of the US stock market as it makes up for around 80% of available market capitalization.
Despite the inclusion of extra TA features and RFE to noticeably increase accuracy, the average test accuracy was still lower than 0.52 – Less than always predicting the majority class. Therefore, if we assume the magnitude of positive and negative return is about the same, then the buy and hold strategy would always yield more return given that we can only buy and sell a stock.
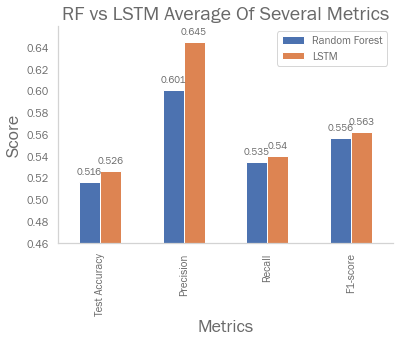
The final method uses LSTM instead of random forest, as LSTM remains a popular model within financial prediction literature. Many metrics see significant improvement:
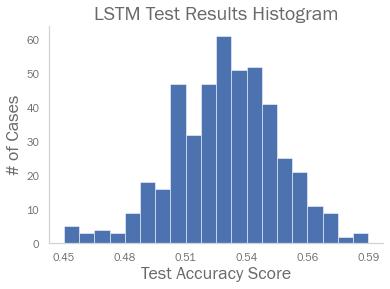
Interestingly, the resulting test accuracy score distribution from the 500 samples produces a shape very close to a normal distribution. This is no surprise given the central limit theorem and that accuracy itself is an average. Moreover, mean and median test accuracy are very close, at 0.5261 and 0.528 respectively.
The average test accuracy is still slightly below the majority class make up. However, the final method needed to generalize the US stock market; this will provide considerable leeway for improvement when the method is applied to a single stock or index given some hyperparameter and feature adjustments.
Unfortunately, this article had concluded that even with 0.65 out-of-sample accuracy score, the predictor was at times not able to outperform the buy and hold strategy when presented to a real trading experiment with higher volatility, when considering trading fees.
Therefore, while the use of the final method will probably present profitable trading strategies, it is not guaranteed. Given brokerage commissions and a constantly changing stock market, basic strategies like buy and hold may have better performance.

